
Rultor is a coding team assistant. Travis is a hosted continuous integration system. In this article I’ll show how our open source projects are using them in tandem to achieve seamless continuous delivery.
I’ll show a few practical scenarios.
Scenario #1: Merge Pull Request
jcabi-mysql-maven-plugin is a Maven plugin for MySQL integration testing. @ChristianRedl submitted pull request #35 with a new feature. I reviewed the request and asked Rultor to merge it into master: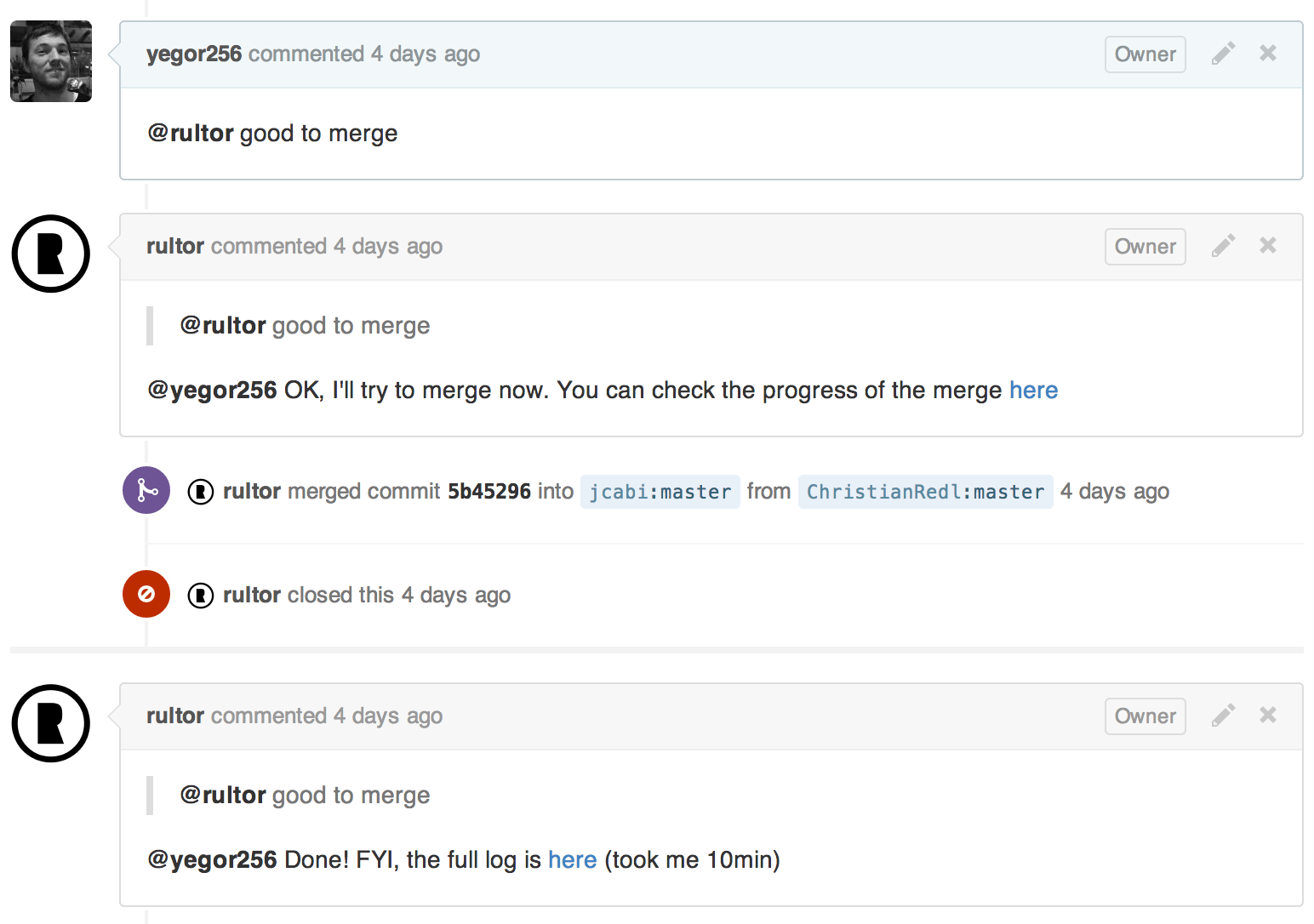
As you can see, an actual merge operation was made by Rultor. I gave him access to the project by adding his GitHub account to the list of project collaborators.
Before giving a “go ahead” to Rultor I checked the status of the pre-build reported by Travis: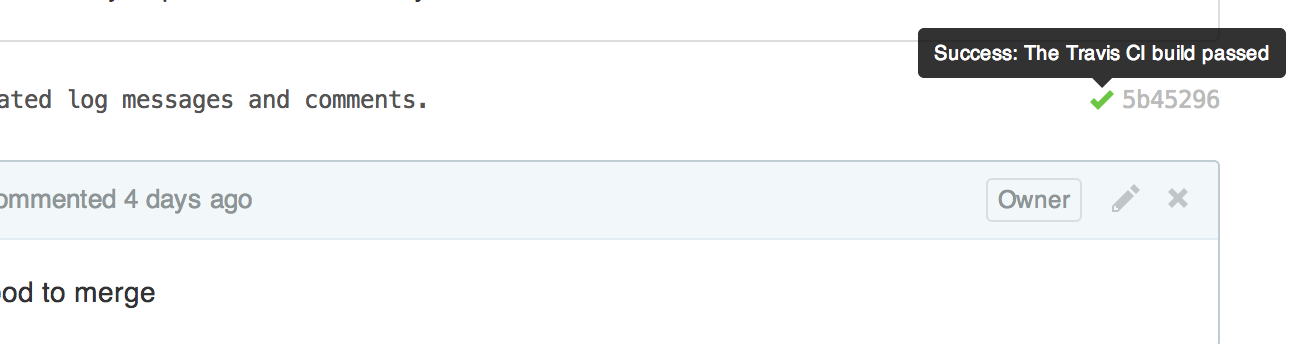
Travis found a new commit in the pull request and immediately (without any interaction from my side) triggered a build in that branch. The build didn’t fail, that’s why Travis gave me a green sign. I looked at that sign and at the code. Since all problems in the code were corrected by the pull request author and Travis didn’t complain—I gave a “go” to Rultor.
Scenario #2: Continuous Integration
Even though the previous step guarantees that master branch is always clean and stable, we’re using Travis to continuously integrate it. Every commit made to master triggers a new build in Travis. The result of the build changes the status of the project in Travis: either “failing” or “passing.”
jcabi-aspects is a collection of AOP AspectJ aspects. We configured Travis to build it continuously. This is the badge it produces (the left one):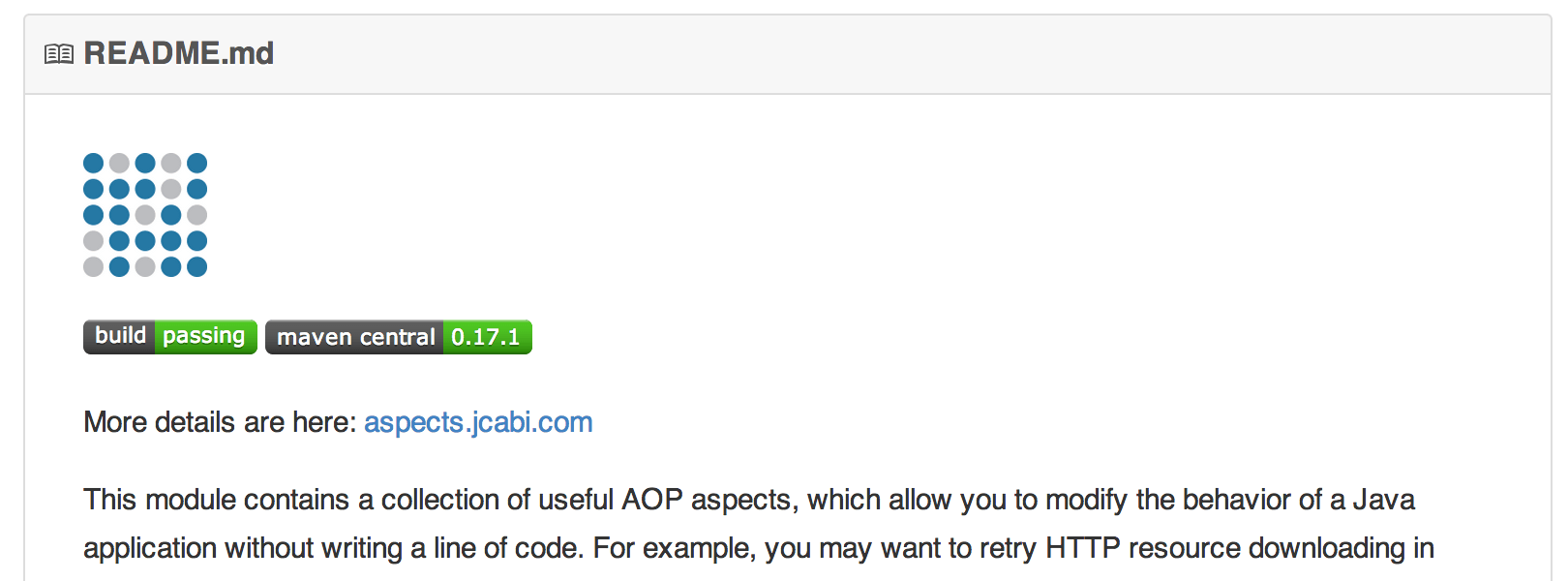
Again, let me stress that even through read-only master is a strong protection against broken builds, it doesn’t guarantee that at any moment master is stable. For example, sometimes unit tests fail sporadically due to changes in calendar, in environment, in dependencies, in network connection qualities, etc.
Well, ideally, unit tests should either fail or pass because they are environment independent. However, in reality, unit tests are far from being ideal.
That’s why a combination of read-only master with Rultor and continuous integration with Travis gives us higher stability.
Scenario #3: Release to RubyGems
jekyll-github-deploy is a Ruby gem that automates deployment of Jekyll sites to GitHub Pages. @leucos submitted a pull request #4 with a new feature. The request was merged successfully into master branch.
Then, Rultor was instructed by myself that master branch should be released to RubyGems and a new version to set is 1.5: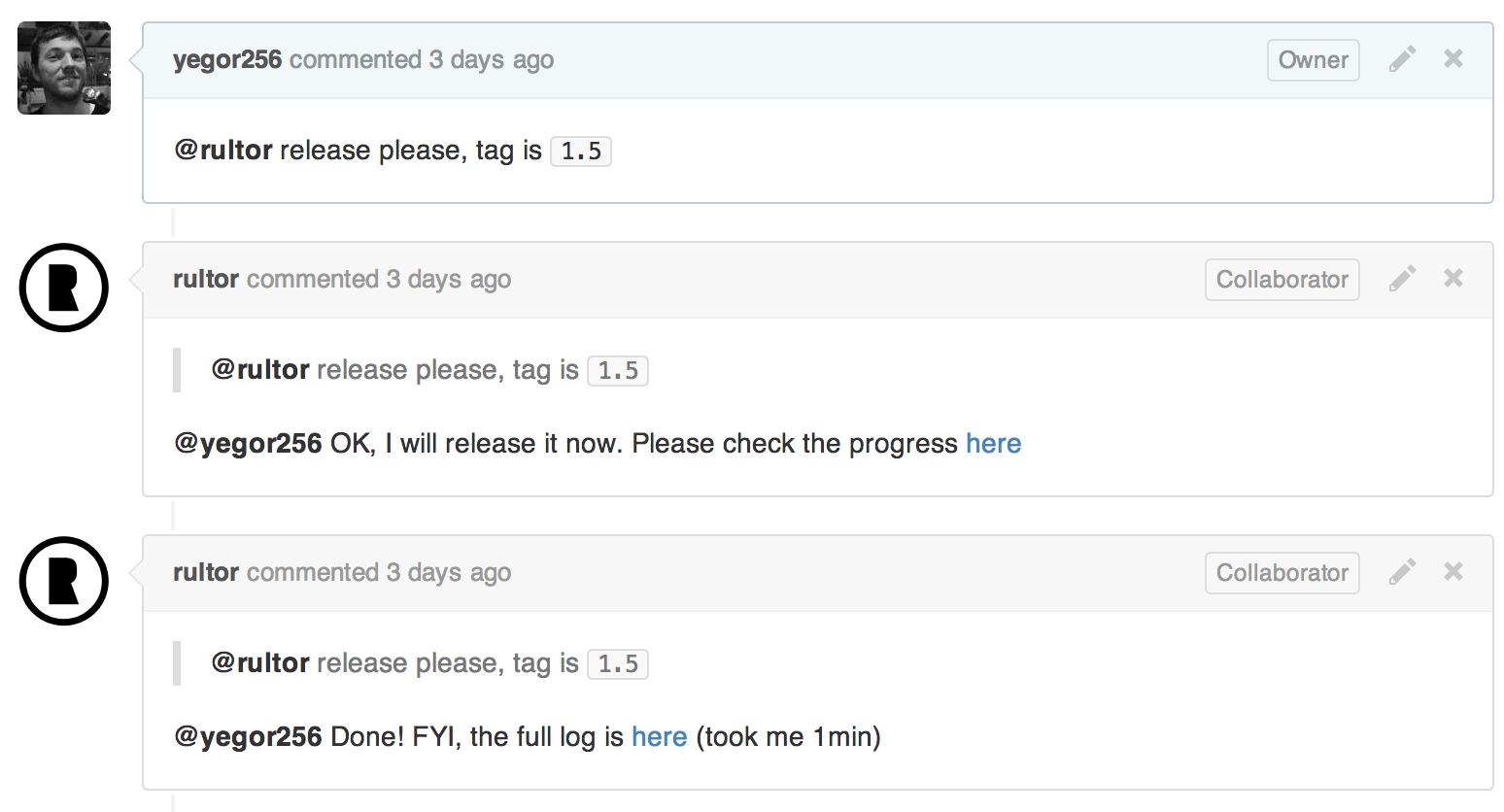
Rultor executed a simple script, pre-configured in its .rultor.yml:
release:
script: |
./test.sh
rm -rf *.gem
sed -i "s/2.0-SNAPSHOT/${tag}/g" jgd.gemspec
gem build jgd.gemspec
chmod 0600 ../rubygems.yml
gem push *.gem --config-file ../rubygems.yml
The script is parameterized, as you see. There is one parameter that is passed by Rultor into the script: ${tag}. This parameter was provided by myself in the GitHub issue, when I submitted a command to Rultor.
The script tests that the gem works (integration testing) and clean up afterwords:
$ ./test.sh
$ rm -rf *.gem
Then, it changes the version of itself in jgd.gemspec to the one provided in the ${tag} (it is an environment variable), and builds a new .gem:
$ sed -i "s/2.0-SNAPSHOT/${tag}/g" jgd.gemspec
$ gem build jgd.gemspec
Finally, it pushes a newly built .gem to RubyGems, using login credentials from ../rubygems.yml. This file is created by Rultor right before starting the script (this mechanism is discussed below):
$ chmod 0600 ../rubygems.yml
$ gem push *.gem --config-file ../rubygems.yml
If everything works fine and RubyGems confirms successful deployment, Rultor reports to GitHub. This is exactly what happened in pull request #4.
Scenario #4: Deploy to CloudBees
s3auth.com is a Basic HTTP authentication gateway for Amazon S3 Buckets. It is a Java web app. In its pull request #195, a resource leakage problem was fixed by @carlosmiranda and the pull request was merged by Rultor.
Then, @davvd instructed Rultor to deploy master branch to production environment. Rultor created a new Docker container and ran mvn clean deploy in it.
Maven deployed the application to CloudBees: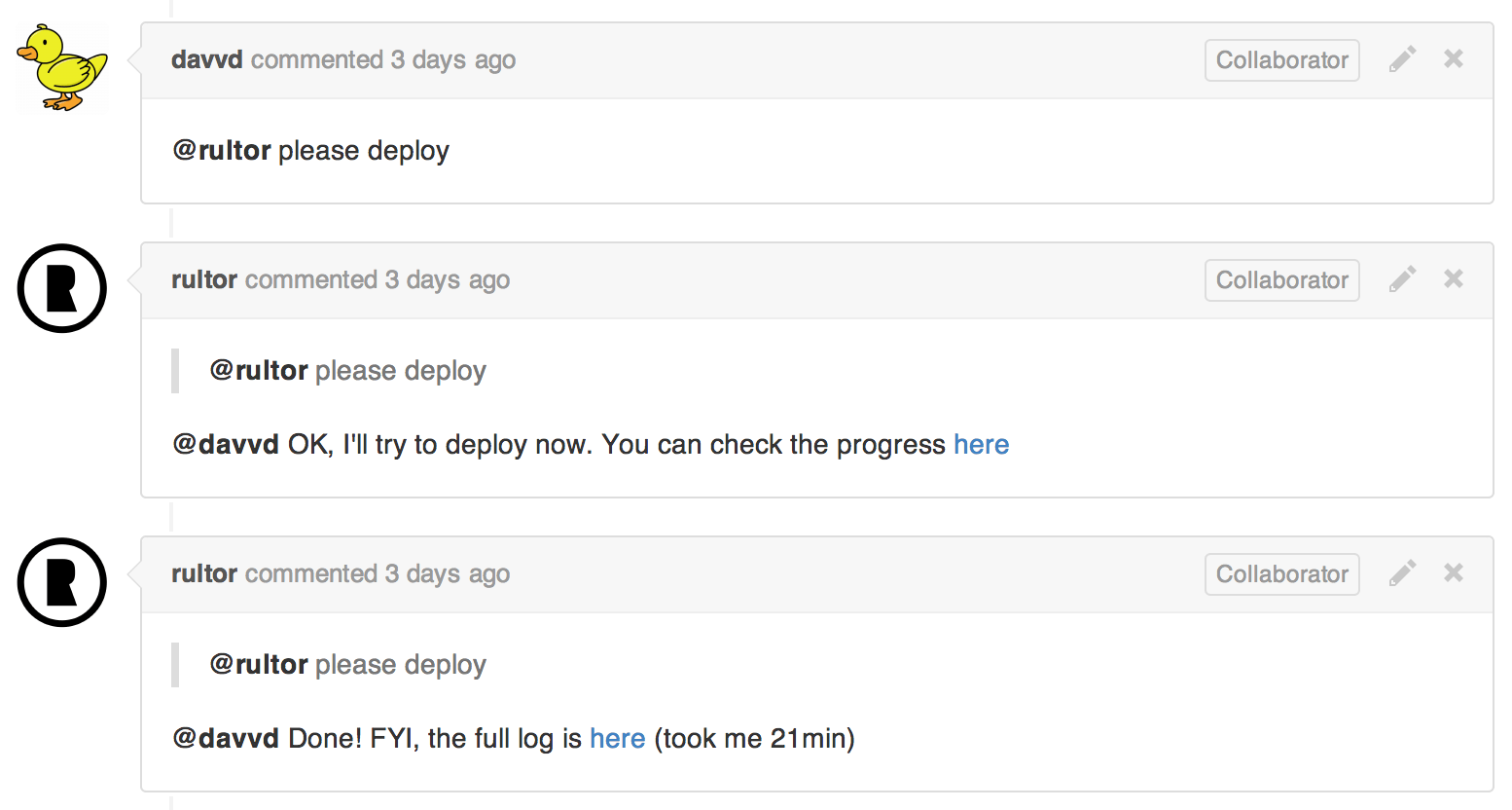
The overall procedure took 21 minutes, as you see the in the report generated by Rultor.
There is one important trick worth mentioning. Deployment to production always means using secure credentials, like login, password, SSH keys, etc.
In this particular example, Maven CloudBees Plugin needed API key, secret and web application name. These three parameters are kept secure and can’t be revealed in an “open source” way.
So, there is a mechanism that configures Rultor accordingly through its .rultor.yml file (pay attention to the first few lines):
assets:
settings.xml: "yegor256/home#assets/s3auth/settings.xml"
pubring.gpg: "yegor256/home#assets/pubring.gpg"
secring.gpg: "yegor256/home#assets/secring.gpg"
These YAML entries inform Rultor that it has to get assets/s3auth/settings.xml file from yegor256/home private (!) GitHub repository and put it into the working directory of Docker container, right before starting the Maven build.
This settings.xml file contains that secret data CloudBees plugin needs in order to deploy the application.
How to Deploy to CloudBees, in One Click explains this process even better.
You Can Do The Same
Both Rultor and Travis are free hosted products, provided your projects are open source and hosted at GitHub.
Other good examples of Rultor+Travis usage can be seen in these GitHub issues: jcabi/jcabi-http#47, jcabi/jcabi-http#48
PS. You can do something similar with AppVeyor, for Windows platform: How AppVeyor Helps Me to Validate Pull Requests Before Rultor Merges Them
